Multi-hop Selector Network for Multi-turn Response Selection in Retrieval-based Chatbots
in Posts on Reviews, Nlp, Deep_learning, Retrieval, Dialogue, Response_selection, Adversarial_dataset
TL;DR:
- The author argues that training model to recognize the relevance between context and response is important for response selection task.
- The overall architecture seems similar with MDFN(Masking Decoupling Fusing Network) in that it fuses information of different level such as word, utterance, and context through attention mechanism.
- The experiments on MSN(Multi-hop Selector Network) showed that weighted utterance representations improved the performance on PLM-based response matching model in general.
Introduction
- Too many topics in a dialogue may confuse and hinder to catch the essence in human conversation. Likewise, in a dialogue system, too much context utterances can be noise to train model select the correct response.
- Some previous experiments showed that model focus on semantic similarity (i.e. common tokens) rather than implicit context. The author proposed Multi-Selector Network(MSN) to address this problem by filtering irrelevant context utterances out.
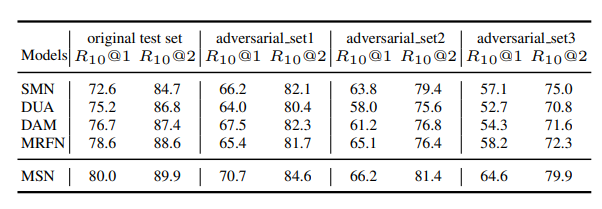
Adversarial Dataset test

- The author constructed adversarial dataset to check whether the model is affected excessively by semantic similarity, common tokens, between context and response, rather than sequential information.
- Adversarial dataset 1~3 indicates the number of tokens which is sampled from context and concatenated to response.
- The result shows that more tokens to be concatenated, more likely to be affected, while MSN is more robust than previous works.
Selector
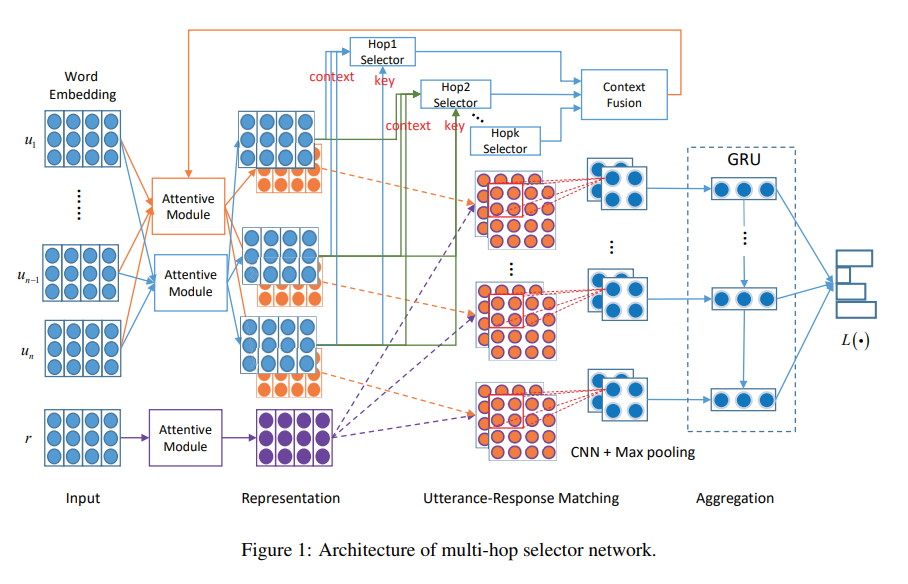
- One of the naive approaches to filter out irrelevant utterances is choosing top-k utterances through an extractive summarization. However, it can not be guaranteed that these top-k utterances contains the essence of conversation unlike formal and informative documents such as news.
- MSN is different in that it weighs the utterances.
- Each selector aims to fuse information on each level such as word, utterance and between utterances.
- HopK is designed to address the case when last utterance in context contains few information (e.g. ‘Good job!’ or ‘OK’) by fusing with utterances from the second last index to the kth.
- Word Selector: pooling over row and column after obtaining cross attention between one of context utterance and response utterance at timestep t
- Utterance Selector: get cosine similarity between the output of word selector and response utterance at timestep t
- Hopk Selector: get cosine similarity between output of word selector and utterance at timestep t-1 … t-k as utterance selector calculates score with utterance at timestep t
- Context Fusion: get score of each utterance by linear transformation of Hop-k Selector output, which is for weighted utterance representations
Conclusion
- The overall architecture seems similar with MDFN(Masking Decoupling Fusing Network) in that it weighs in different level such as word, utterance, and context through attention mechanism.
- Selector technics improved performances consistently regardless of its based PLMs.
- This approach is effective for supplement of insufficient information in last utterance, as well as denoising the interference of irrelevant utterances.
Reference and Implementation:
- paper: Multi-hop Selector Network for Multi-turn Response Selection in Retrieval-based Chatbots, 2019
