Do Response Selection Models Really Know What's Next? Utterance Manipulation Strategies for Multi-turn Response Selection
in Posts on Reviews, Nlp, Deep_learning, Retrieval, Dialogue, Response_selection, Auxiliary_task
TL;DR:
- UMS-BERT is one of approaches suggesting complementary training tasks, in order to deal with the limitation of learning sequential information.
- There was performance gain in both PLM based model and non-PLM based model, which means that the auxiliary tasks are substantial to enhance the capabilities for dialogue response selection.
- The background of paper, such as proposed problem, approach, and conclusion seems quite similar with BERT-SL.
Introduction
- As previous works diagnosed, the author addressed the insufficient learning of implicit knowledge on dialogue characteristics as the critical limitation of current dialogue models. The author proposed the auxilary tasks for multi-task learning rather than the modification of architecture in order to tackle the inefficiency of soley training on binary classification.
UMS Strategies
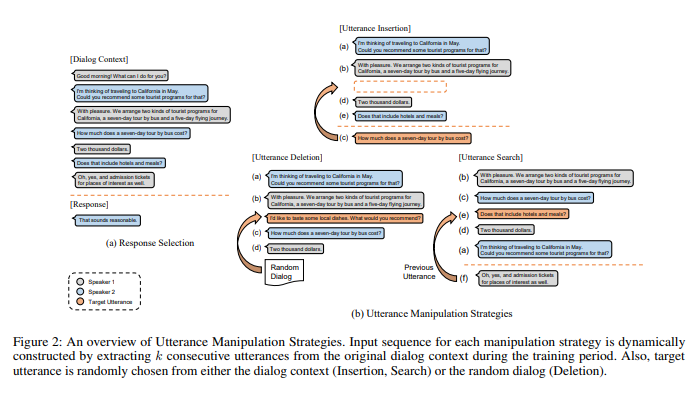
- Below three self-supervised auxilary tasks focus on preventing the model from being biased in learning and capable to unterstand only the semantic similarity, which help the model to learn temporal dependencies between utterances. The final loss is determined by summing the response selection loss and below losses with the same ratio.
- Insertion:
- purpose: learn to discriminate whether the utterances are consecutive even if they are semantically related
- implementation: randomly pop one utterance among $k$ consecutive utterances, and predict the position of target utterance with $[INS]$ token, which appears right in front of every utterances
- Deletion:
- purpose: enrich utterance-level interaction in multi-turn conversation by discriminating irrelevant utterance among context
- implementation: insert an utterance from a random dialog among the $k$ consecutive utterances, and predict the position of irrelevant utterance with $[DEL]$ token, which appears right in front of every utterances
- Search:
- purpose: learn temporal dependencies between semantically similar utterances
- implementation: shuffle $k$ consecutive utterances except for the last utterance, and prediction the position of the previous utterance of the last utterance with $[SRCH]$ token, which appears right in front of every utterances
- Insertion:
Conclusion
- Four metrics have been used: ${R_{10}}@1$, MAP (Mean Average Precision), MRR (Mean Reciprocal Rank), and $P@1$ (precision at one)
- The models with UMS consistently show performance improvement regardless of which PLM was used for base model, or wheter language models are post-trained on each corpus or not. It seems that UMS strategies are the significantly efficient training tasks to discriminate semantic differences as well as select coherent response through traininig to learn which utterance does not suit the conversation. In addition, Deletion task shows more concrete improvement among three tasks.
- However, The models without post-training show different result by dataset, which can be explained that post-training on domain-specific corpus provides the model with more opportunities to learn the relevance through NSP as the effect of data augmentation.
Ablation
- The most interesting part of this paper is the adversarial experiment. As the author set the initial goal as learning utterance-level relevance rather than semantic similarity, he construct the adversarial dataset, which consists of more challenging batch set unless the model learn the sequential information enough. The adversarial set of $n$ utterances consists of one gold response, one random utterance among context utterances (adversarial response), and $n-2$ negative responses.
- The overall performance on adversarial test set dropped compared to original set. If the model allocate lower probability to adversarial sample, we can estimate that the model learned the sequential information better. First, the performance of the models trained through ums strategies dropped less than others. Second, ELECTRA based model is less likely to allocate high probability to adversarial response than BERT based model. Two assumptions can be deduced. one is that NSP (Next Sentence Prediction) task in BERT overfits the model to predict semantically relevant sentence rather than the consecutive sentence, and the other is that replaced token detection is more effective in representing contextual information from the sequence.
Reference and Implementation:
- paper: Do Response Selection Models Really Know What’s Next? Utterance Manipulation Strategies for Multi-turn Response Selection, 10 Sep 2020
