Filling the Gap of Utterance-aware and Speaker-aware
in Posts on Reviews, Nlp, Deep_learning, Retrieval, Dialogue, Response_selection
TL;DR:
- Mask-based Decoupling-Fusing Network (MDFN) is one of architecture-side approaches to deal with the limitation of learning sequential information.
- Decoupling and fusing mechanism is proposed for model to encode utterance-level and speaker-level information.
Introduction
- The most critical point for substantial response selection the author argues is that encoding information according to its source, such as utterances or speaker. Mask-based Decoupling-Fusing Network (MDFN) is the architecture to contextualize the information in multiple channels.
The limitation of the existing approaches
- Adding classifier after concatenation of the response and context directly, the most common approach, is not a capable with limitations belows.
- First, they do not take into account the transition, such as speaker role transitions in multi-turn dialogue, which will lead to the ambiguity of coherence.
- Second, the further inherent meaning beside the explicit information can be reduced by understanding local and global meaning respectively.
- It means that the model cannot faithfully reflect the additional information, such as positional or turn order information, and may cause entanglement of that information belongs to different parts.
Mask-based Decoupling-Fusing Network (MDFN)
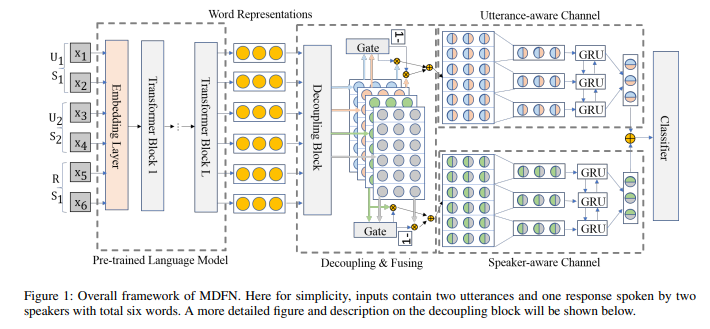
- MDFN consists of six parts: Encoding(BERT or ELECTRA), Decoupling(masking), Fusing(gating), Word Aggregating(Max-pooling), Utterance Integrating(BiGRU), and Scoring(classifier).
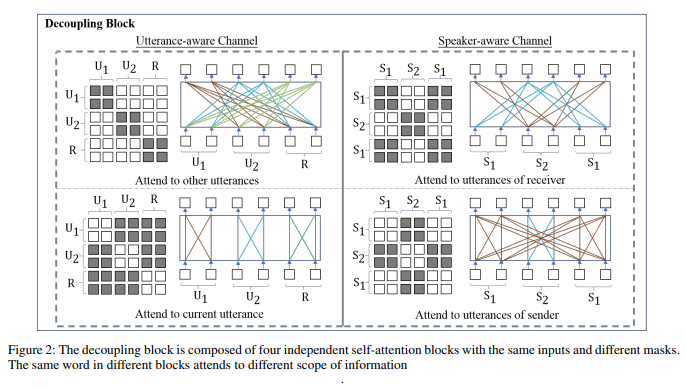
- The author adopted the masking mechanism inside self-attention network to decouple the contextualized words representations into four parts containing different information, two utterance-aware channels and two speaker-aware channels, mitigating focus of each word only on the words. The gating mechanism is adopted to fuse the information inside each channel again after sufficient interactions, and BiGRUE at the last part of model is adopted to get the dialogure-level representations.
- The figure in the paper is efficient to understand whole architecture since the mechanisms adopted are quite simple and clear.
Conclusion and additional experiments
- MDFN outperforms other models in Rn@k (the proportion of TP response among the top-k selected responses from the list of n available candidates), MAP(Mean Average Precision), and MRR(Mean Reciprocal Rank) in general.
- Belows are empirical conclusions of each adoption.
- One decoupling layer is enough and better than deeper. (It seems deeper stacking of layers make harder to learn)
- Deeper BiGRU causes a drop on a metric. (a short sequence seems to be already contextualized enough with shallow BiGRU)
- The gating mechanism do its functionality faithfully. (two kinds of information are inherently complementary, and the original information can be a good reference to calculate gate ratio since decoupling information can be seen as a transformation from original one)
- Max-pooling is better than mean-pooling, and CNN-based method. (it can be explained that it can preserve some activated signals removing the disturbance of less important signals, and the shared filters between different sentences of convolution layers is not flexible enough and cannot generalize well)
- Altering the underlying PLMs has not affected the result significantly, which means that MDFN is generally effective to the widely-used PLMs.
Reference and Implementation:
- paper: Filling the Gap of Utterance-aware and Speaker-aware, 14 Sep 2020
