RocketQAv2, A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
in Posts on Reviews, Nlp, Deep_learning, Retrieval, Distillation
TL;DR:
- RocketQAv2 is the two-stage retrieval system for Question-Answering task.
- The author proposed ‘Dynamic List-wise Distillation’ and ‘Hybrid Data Augmentation’ utilizing the previous version, RocketQAv.
Retrieval and Re-rank
- One of the most common architecture of Question-Answering system is two-stage selection which consists of retrieval and rerank. After the retriever select top-k candidates, the re-ranker elaborates the score and return the most proper candidate among them. There are some advantages of this appraoch. The first is that it can reduce computational time of reranking by sampling top-k candidates with retriever since re-ranker took more times than retriever in usual, and the second is that it can further enhance the end-to-end performance by making the reranker focus on scoring of small batches.
Introduction
- The retriever and re-ranker, two important components of existing retrieval systems, should be jointly optimized. However, retriever is trained by pointwise or pairwise training and re-ranker by listwise training in usual. The author proposed a unified listwise training approach for both retriever and re-ranker and sampling strategy to constructive hard negative batches, which enables two components can be adaptively improved according to each other’s relevance information, that is dynamic joint distillation.
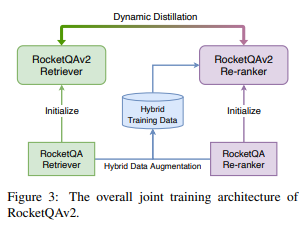
Contribution
- It has been observed that joint distillation is useful to train two components in a corrleated manner considering the fact that the two modules work as a pipeline during the inference stage. The dynamic listwise distillation optimize the gradients of two modules simultaneously based on the entire list of positive and negatives in a batch unlike the static distillation freezing one module while updating the gradients of another.
Dynamic Listwise Distillation
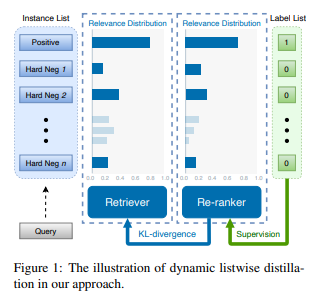
- The two major assumptions of this technique are that incorporating hard negatives during training enhance the model’s capability and that distilling the knowledge from cross-encoder-based reranker into dual-encoder-based retriever.
- The main idea is to minimize the KL-divergence between the two normalized relevance scores of query over candidates, $\tilde{S_{de}}(q, c)$ from dual-encoder and $\tilde{S_{ce}}(q,c)$ from cross-encoder, which means the estimated relevance distribution(i.e. soft labels) is utilized for relevance distillation. So, the final loss function is the combination of the KL-divergence loss and the supervised crossentropy loss discriminating a positive sample over other negative samples. Besides, the author suggests to update parameters of the re-ranker dynamically in order to shynchronize the two modules adaptively for mutual improvement according to the final retrieval performance.
Hybrid Data Augmentation
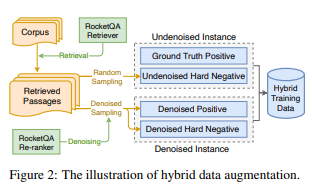
- The key idea is to construct diverse training instances by incorporating both denoising sampling and undenoising (random) sampling. For undenoised sample, the author samples randomly the hard negatives from retrieved candidates from retriever. In this paper, the author utilized RocketQA, the previous version of current paper. For denoised sample, the predicted negatives with low confidence scores by retriever are removed. The data construction strategy improve diversity and make optimization task more difficult.
Conclusion
- Dynamic listwise distillation enables the retriver to capture the re-ranker ability of candidat ranking at op ranks. Also, the author showed that PLM of retriever and reranker is not the factor for improvement by experiements of two methods employing the same backbone PLM, which indicaes that joint optimization through dynamic listwise distillation is significantly effective. In addition, it has been observed that a large number of instances (i.e. number of hard negatives) improves the performance.
Reference and Implementation:
- paper: RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking, 14 Oct 2021
